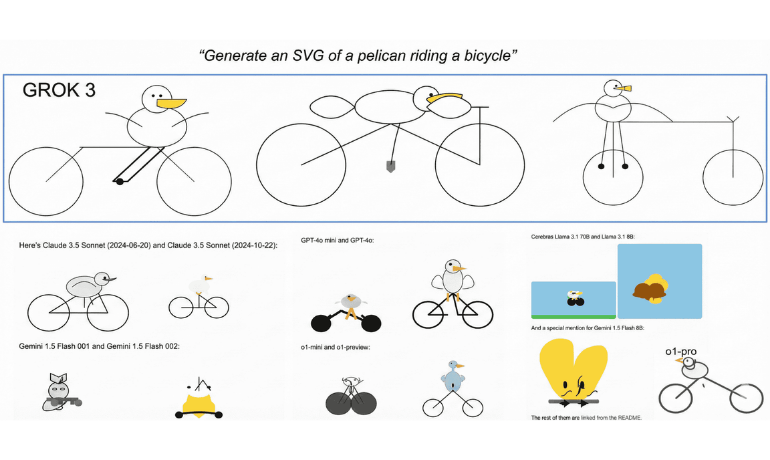
The pelican on a bicycle began as a practical test, not a joke. Simon Willison, co creator of the Django framework and creator of Datasette, was exploring how large language models behave when asked to generate structured visual output.
The pelican on a bicycle began as a practical test, not a joke. Simon Willison, co creator of the Django framework and creator of Datasette, was exploring how large language models behave when asked to generate structured visual output. Rather than producing pixels, the task required generating valid SVG code. Every shape, coordinate, and relationship had to be planned explicitly. There was no diffusion process to smooth over mistakes. The result either made sense as a composed scene, or it didn’t.
Why a pelican, and why a bicycle
The choice of subject was deliberate. A pelican has awkward proportions: a long beak, a heavy body, thin legs, and an unusual silhouette. Placing that body on a bicycle introduces strict spatial constraints. Wheels must align, frames must connect, limbs must interact with pedals and handlebars, and the entire composition must suggest balance.
This single prompt compressed multiple difficult problems into one request. It tested spatial reasoning, compositional planning, symbolic representation, and code generation at the same time.
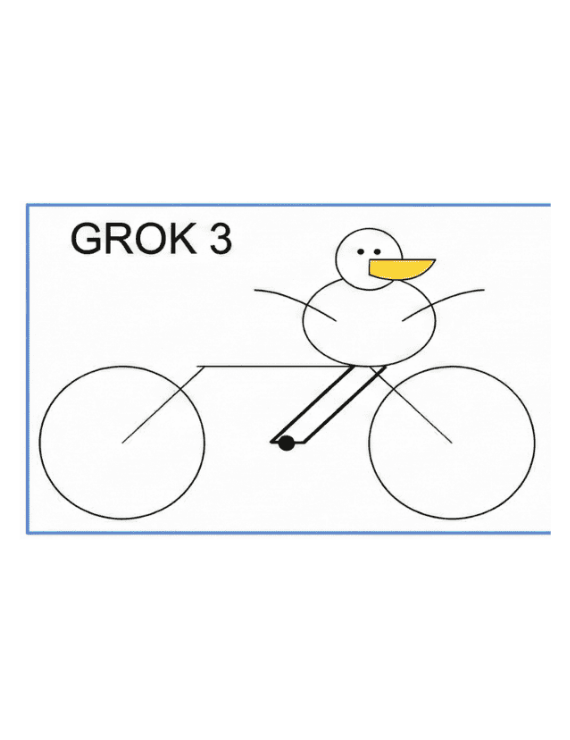
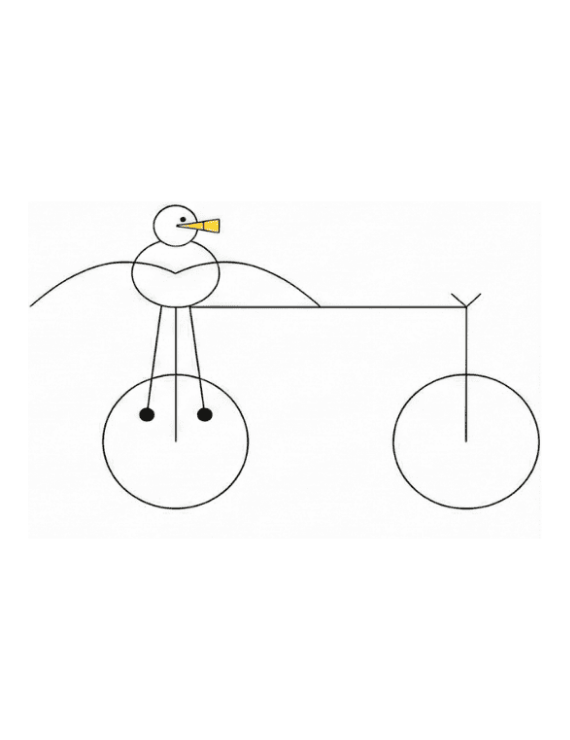
This prompt became a shared reference point inside the AI community.
As the prompt circulated, developers and researchers began using it as a quick diagnostic when evaluating new image and multimodal models. It was never formalized as a benchmark, but it didn’t need to be. The task was intuitive. You could look at the result and immediately understand what worked and what didn’t. That accessibility made it sticky.
It’s a surprisingly good test of whether a model understands structure, not just appearance.
Andrej Karpathy - Former Director of AI at Tesla, Founding team OpenAI.
When Andrej Karpathy referenced the pelican while testing systems such as Grok, it confirmed what many practitioners already felt. The prompt had become a kind of folk benchmark. Informal, non standardized, but widely understood.